By James Kwak
In 1975, Isaac Ehrlich published an empirical study purporting to show that the death penalty saved lives, since each execution deterred eight murders. The next year, Solicitor General Robert Bork cited this study to the Supreme Court, which upheld the new versions of the death penalty that several states had written following the Court’s 1973 decision nullifying all existing death penalty statutes. Ehrlich’s results, it turned out, depended entirely on a seven-year period in the 1960s. More recently, a number of studies have attempted to show that the death penalty deters murder, leading such notables as Cass Sunstein and Richard Posner to argue for the maintenance of the death penalty.
In 2006, John Donohue and Justin Wolfers wrote a paper essentially demolishing the empirical studies that claimed to justify the death penalty on deterrence grounds. Donohue and Wolfers attempted to replicate the results of those studies and found that they were all fatally infected by some combination of incorrect controls, poorly specified variables, fragile specifications (i.e., if you change the model in minor ways that should make little difference, the results disappear), and dubious instrumental variables. In the end, they found little evidence either that the death penalty reduces or increases murders.
Now the macroeconomic world has its version of the death penalty debate, in the famous paper by Carmen Reinhart and Ken Rogoff, “Growth in a Time of Debt.” Thomas Herndon, Michael Ash, and Robert Pollin released a paper earlier this week in which they tried to replicate Reinhart and Rogoff. They found two spreadsheet errors, a questionable choice about excluding data, and a dubious weighting methodology, which together undermine Reinhart and Rogoff’s most widely-cited claim: that national debt levels above 90 percent of GDP tend to reduce economic growth.
I’ve never been a big fan of Reinhart-Rogoff. In White House Burning, we cited their main result but added (p. 151),
“It is hard to know what it means for the United States because even their findings for advanced economies are the averages over sixty years of twenty different countries—nineteen of which did not enjoy the particular benefits of issuing the world’s reserve currency.”
Now it turns out that the averages were wrong. To see how, you can read Herndon et al. (it’s very short and readable) or the excellent post by Mike Konczal. If you don’t want to do that, there are four basic issues:
- The 2010 Reinhart and Rogoff paper excluded data for certain countries and years that, when included, increase mean growth for debt levels greater than 90 percent. (In their response, Reinhart and Rogoff say that those country-years were not available when they did the original paper.)
- The results were averaged by country and then the country averages were themselves averaged. The problem here is that, for example, New Zealand only had debt above 90 percent in one year, and in that year its growth was –7.6 percent—but since only ten countries ever had debt over 90 percent, that outlier constituted one-tenth of the average.
- Their spreadsheet formula accidentally omitted several countries; including those countries increases the average growth level for debt levels over 90 percent.
- One figure—New Zealand’s—was mistranscribed from one spreadsheet to another; correcting that mistake slightly raises the average growth level.
Leaving aside the Excel problem for now, I think this points to a weakness of the original methodology. The paper was, technically speaking, extremely simple: take all the country-years, divide them into four groups by debt level, and average within each group. I thought at the time that if an economics graduate student tried to submit this as part of a dissertation, it would never be accepted. I remember looking at this chart and thinking: So what? Does that prove anything? How do I know that this is significant—especially since the mean and the median are so different? (Usually if the mean is very different from the median, it is being dragged up or down by some huge outlier.)
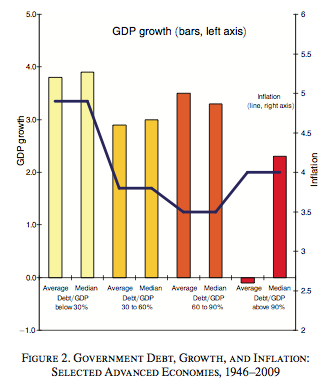
Like most people, I think, I thought they were averaging by country-year, not country. Averaging by country obviously makes the results even more sensitive to outliers. Reinhart and Rogoff claim in their response that this is a standard approach; maybe it is. But this is what the paper says (emphasis added):
“The annual observations are grouped into four categories, according to the ratio of debt to GDP during that particular year as follows: years when debt to GDP levels were below 30 percent (low debt); years where debt/GDP was 30 to 60 percent (medium debt); 60 to 90 percent (high); and above 90 percent (very high). The bars in Figure 2 show average and median GDP growth for each of the four debt categories. Note that of the 1,186 annual observations, there are a significant number in each category, including 96 above 90 percent.”
I think the most natural reading of this passage is that they were averaging individual country-year observations, not countries.
The other surprising thing, of course, is that they were using Excel (or some other spreadsheet program)—something that I wrote about recently. The attraction of Excel is that it’s visually intuitive, it’s powerful, and it’s fast. The problem is that it’s very easy to make mistakes, it doesn’t have any usable kind of versioning, and there’s no good way to proofread or test it. As Herndon et al. write with considerable understatement, “For econometricians a lesson from the problems in RR is the advantages of reproducible code relative to working spreadsheets.” And if you’re going to use Excel for anything important (like counseling economic policymakers), you’d better be damn good at it. For example, you shouldn’t be manually copying numbers from one tab to another (an error shared by Reinhart and Rogoff with the risk management department of JPMorgan’s Chief Investment Office).
This raises another issue. Programming is getting easier and easier, but it’s hard to do well. Economics these days depends heavily on programming. It seems to problematic to me that we rely on economists to also be programmers; surely there are people who are good economists but mediocre programmers (especially since the best programmers don’t become economists). If you crawl through a random sample of econometric papers and try to reproduce their results, I’m sure you will find bucketloads of errors, whether the analysis was done in R, Stata, SAS, or Excel. But people only find them when the stakes are high, as with the Reinhart and Rogoff paper, which has been cited all around the globe (not necessarily with their approval) as an argument for austerity.

If R&R took econometrics 201 they wouldn’t have made such a noob mistake.
The degree of correlation between debt and growth does not appear to be all that great from a 30% debt/GDP ratio on up. Most of the correlation is generated by the <30% bin. The question is – how many countries in the modern era have debt/GDP ratios below 30% and how representative are they of the population of economies?
You can go to Wikipedia and sort by debt/GDP ratio:
http://en.wikipedia.org/wiki/List_of_countries_by_public_debt
There are not a lot of countries in that category. What you do see are countries like Libera, Botswana, and Haiti along with Saudi Arabia, Kuwait, and Russia. It's not difficult to draw an inference as to what is happening here.
They’re using Excel?! That’s like using an office paper stapler to frame a house. Why not use R, Minitab, Mathematica, MathLab or SAS? This is embarrassing. More than two years have passed since publication. How many versions of the working paper were circulated for comment? Who were the referees and where the hell were they? These errors are rookie mistakes made while using an inappropriate tool. This paper would’ve been rejected as a doctoral dissertation (I hope). More than embarrassing, this is sad, especially because of how the original paper was used and the author’s hapless defense of their methods.
From the link (http://www.nextnewdeal.net/rortybomb/researchers-finally-replicated-reinhart-rogoff-and-there-are-serious-problems), it looks like the chief years excluded were in the 1940’s. Unless data from the 1940’s were not available in 2010, Reinhart and Rogoff seem to have quite deliberately excluded data contrary to their hypothesis, and did so without disclosing it.
“Selective Exclusions. Reinhart-Rogoff use 1946-2009 as their period, with the main difference among countries being their starting year. In their data set, there are 110 years of data available for countries that have a debt/GDP over 90 percent, but they only use 96 of those years. The paper didn’t disclose which years they excluded or why.
Herndon-Ash-Pollin find that they exclude Australia (1946-1950), New Zealand (1946-1949), and Canada (1946-1950). This has consequences, as these countries have high-debt and solid growth. Canada had debt-to-GDP over 90 percent during this period and 3 percent growth. New Zealand had a debt/GDP over 90 percent from 1946-1951. If you use the average growth rate across all those years it is 2.58 percent. If you only use the last year, as Reinhart-Rogoff does, it has a growth rate of -7.6 percent. That’s a big difference, especially considering how they weigh the countries.”